Is steganography still a thing? I used to think it was just an academic flex, but this guy said 5 years ago it’s used by malware, and he got upvoted, so it must be true 😏.
If you’ve ever hidden data inside an image (couldn’t you find anything more exciting to do with your time?), you know the usual drill: find the edges, hide your stuff there, and hope it’s secure. The problem? Traditional methods don’t let you embed as much data as you’d want, especially with big datasets. Enter prediction error space (PES), a new approach that finds more edges and hides more data. This could boost malware payloads—so maybe that guy was onto something.
This method, outlined in a study by Habiba Sultana & co., is about squeezing every bit of capacity out of edge pixels.
Why Steganography Loves Edges
Edges in images are perfect for hiding data because they’re visually busy. Your eyes don’t notice tiny tweaks in those areas, making them ideal for sneaky embedding. The catch? Traditional edge detectors like Canny or Sobel only find so many edges, capping how much data you can hide.
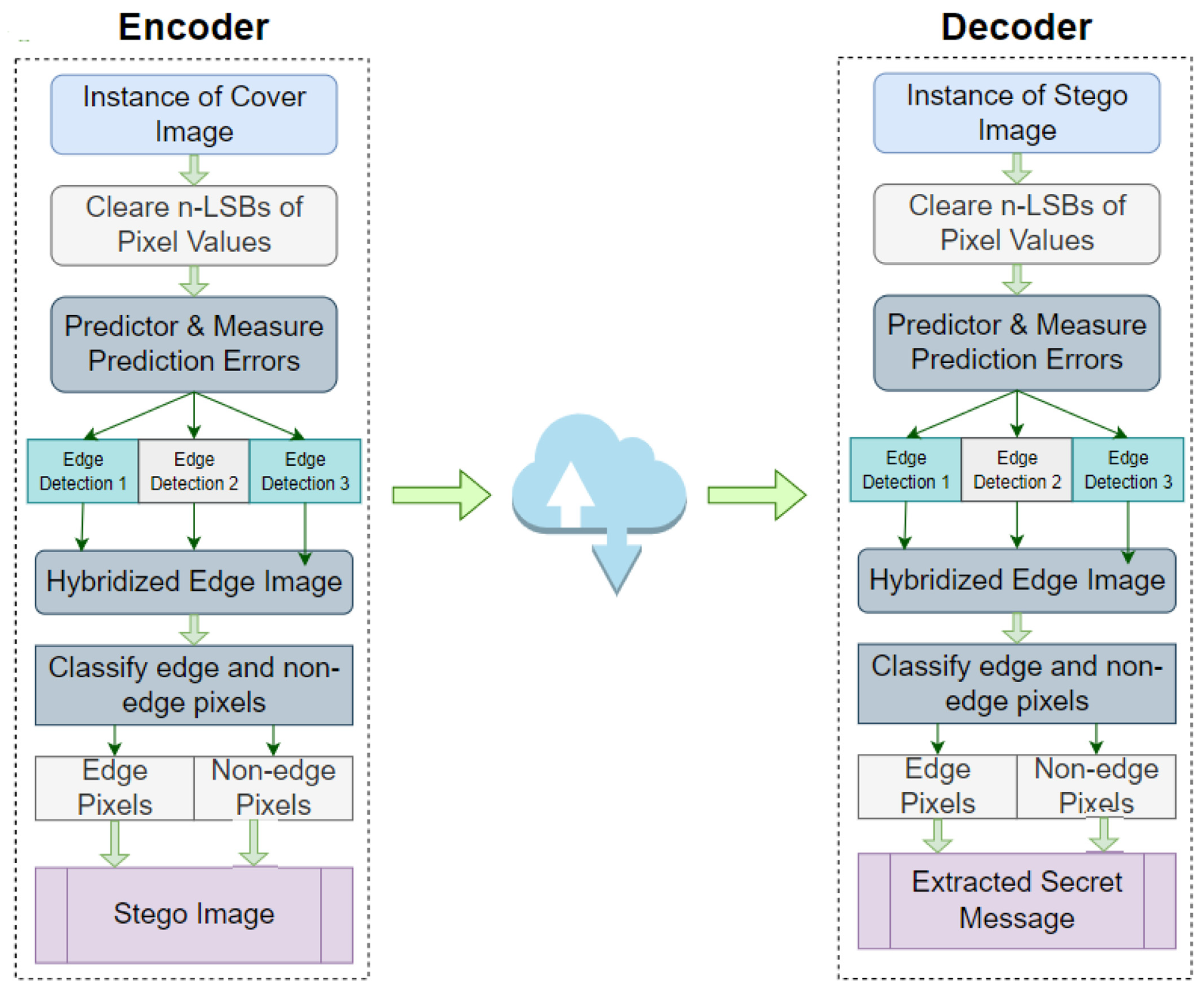
What’s Different About Prediction Error Space?
This method flips things around. Instead of running edge detection directly on the image, it first analyzes “prediction errors”. Basically, it checks how much each pixel deviates from its predicted value (based on its neighbors). This reveals more edge-like areas in the image.
How It Works (The Non-Mathy Version)
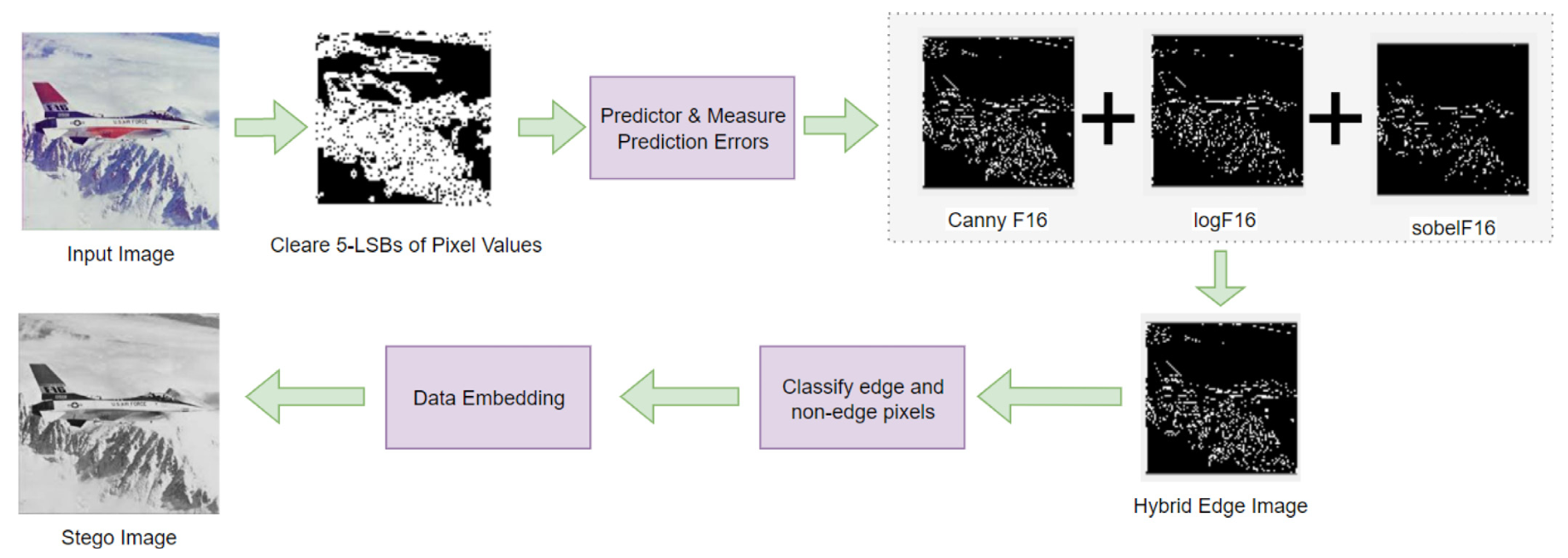
Here’s the gist, without diving into equations:
-
Prep the Image: Strip out some least significant bits, the ones people don’t notice anyway.
-
Find More Edges: Use the prediction errors to run edge detection (e.g., Canny, Sobel). Combine results from multiple detectors using logical operations to uncover even more edges.
-
Hide the Data: Embed more bits in edges than in smooth areas, keeping the image looking normal.
-
Extract the Data: Reverse the process to retrieve your hidden data intact.
Why This Approach Wins
This isn’t just some incremental improvement. Compared to older methods, this one:
- Doubles the edge pixels: More edges mean more data.
- Keeps image quality intact: Even with higher embedding rates, image quality metrics stay strong.
- Handles attacks better: It resists statistical analysis, making it tougher for anyone to spot the hidden data.
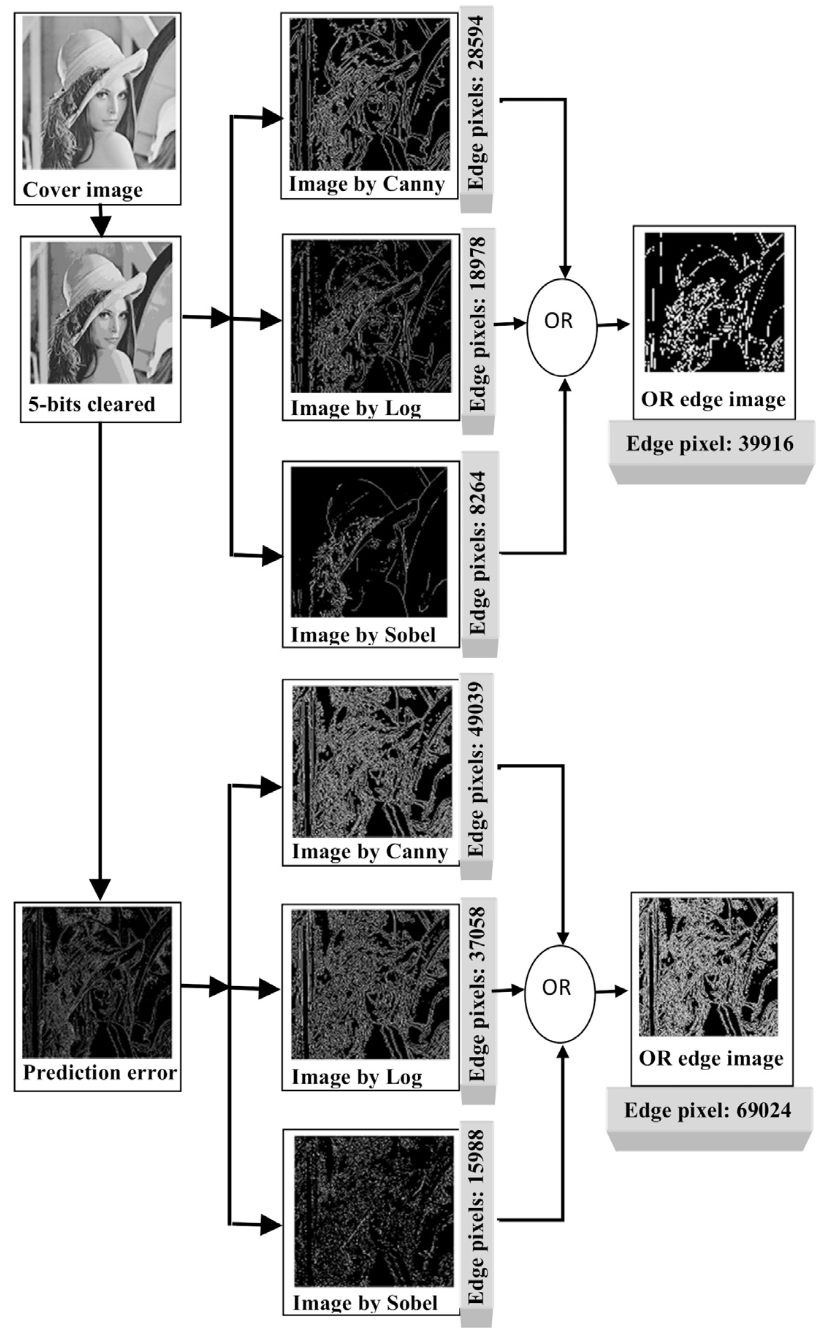
For example, using the famous “Lena” image, this method found significantly more edges than traditional techniques, allowing way more data to be embedded without wrecking the image.
Where It Fits
Turns out this isn’t just for researchers, there are legit applications, like secure messaging or watermarking. Even Instagram.
This prediction error space trick is a smart way to improve steganography. It’s not about reinventing the wheel, it’s about making it roll better. If you’re into data security and steganography, this is worth keeping an eye on, especially with the developments in the area of compression resistant steganography.